
Alec Zimmer
Published
November 5, 2019

SSN Background
When detecting synthetic fraud, it is particularly satisfying to uncover a fraud ring that has been working together to target a lender. One way that we detect this is by using patterns in the applicants’ social security numbers (SSNs) to infer whether there is some common group of fraudsters behind them. To explain how we do this, we’ll first have to cover some technical details about SSNs.
SSNs have a structure that most people don’t know about: for SSNs issued until 2011, the first 3 digits of your SSN indicate where the SSN was issued, and the next 2 digits provide additional information about when the SSN was issued. In this way, the first 5 digits of the SSN, which we at SentiLink refer to as the SSN5, correspond to information about where and when an SSN was issued. In 2011, the Social Security Administration switched to issuing randomized SSNs. The SSN5 will let you know that the SSN was randomly issued after June 2011, but does not provide more granular information about when or where the SSN was issued. An unfortunate side effect of this change is that it is now easier to come up with a plausible looking fake SSN. If you pick an SSN reserved for random issuance for your synthetic identity, you probably don’t have to worry about that SSN belonging to someone else since only a small subset of the random-issuance SSNs have been issued so far. Additionally, most of these recent SSNs have been issued to children, so financial institutions would not yet know the true owners of these SSNs. Moreover, by picking a randomized SSN there aren’t concerns that the SSN you pick was actually issued before your supposed date of birth.
SSN5 Fraud Ring Detection
However, fraudsters can reveal themselves in other ways. One pattern that we’ve observed is fraud rings reusing the same SSN5 for different synthetic identities. Once a fraud ring finds an SSN5 that seems to work, they may keep using it.
Additionally, fraud rings will tend to focus on financial institutions where they’ve had success in the past. If one synthetic identity is able to pass verification and take out a loan, the fraudster or fraud ring will be encouraged to apply to that lender with other synthetic identities they have created. This creates patterns that give away the fraud ring: if the SSN5 is used substantially more often than expected randomly, then something unusual is occurring. We capture and account for these patterns using velocity variables.
Technical Exposition
Readers not interested in technical details can skip ahead to “Reflections”.
One can model the distribution of SSN5s within a certain application window as a multinomial distribution. Creating some notation, let N be the number of of application identities with randomly issued SSNs considered (which we are holding fixed, and have either deduplicated by identity or SSN). Most people are not using randomly issued SSNs, so this N will be much smaller than the total number of loan applications in this timeframe. The categories of your multinomial distribution are the different randomized SSN5s. To detect an unusually high incidence of SSN5s, look at the one-sided p-value for having as many occurrences of that SSN5 as one would expect by chance. Any of these individual hypothesis tests is equivalent to the one-sided p-value for having that many occurrences of that SSN5 under a binomial distribution with the same probability.
Using scipy in Python, this becomes
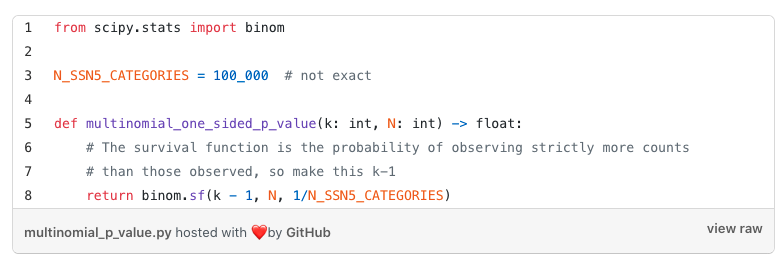
where k is the number of occurrences of the SSN5 under consideration. Of course, you’ll want to adjust whatever you normally think of as a natural p-value to avoid false positives and p-hacking concerns. For example, here’s a simple simulation when we have 5000 simulated randomly issued SSN5s:
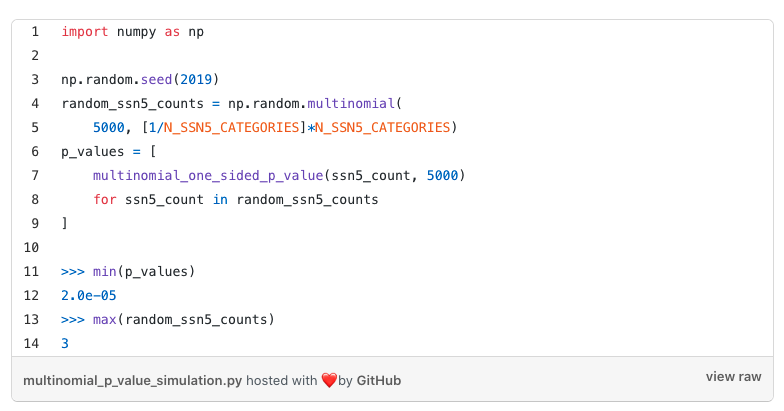
When we look at the most extreme p-value, we get the value of 2e-5, which corresponds to just 3 occurrences of that SSN5. Of course, testing 10⁵ different hypotheses, it’s unsurprising that we’d get a value like this by chance. The simplest correction to make would be the Bonferroni correction to control the familywise error rate: multiply these p-values by the number of tests, which is the number of SSN5s (100,000). In this example, all our p-values are above 1, so under commonly used cutoffs you would not flag any SSN5.
How many occurrences would it take to trigger this feature? At 4 occurrences of an SSN5, we get an adjusted p-value of 0.025, and at 5 occurrences an adjusted p-value of 0.00025.
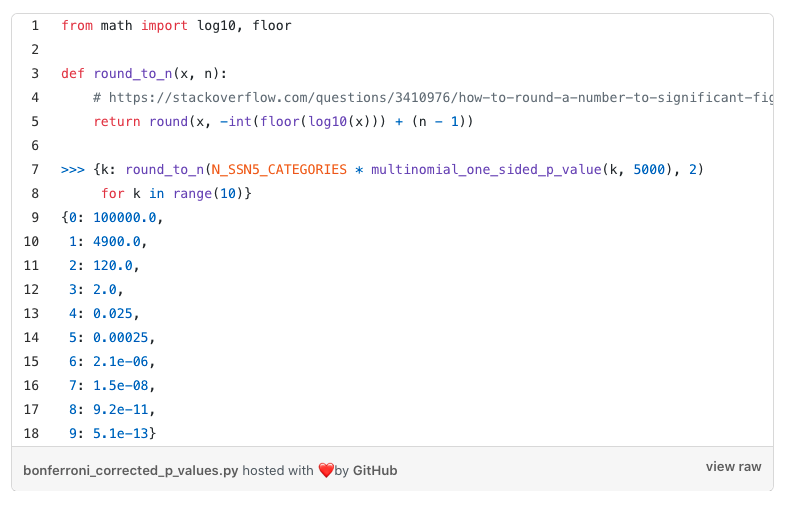
There is a 95.1% chance for a given SSN5 that, under a totally random distribution, we would end up with 0 observations of an SSN5 (the above numbers show a 1-sided p-value of 0.049 for a count of 1). So using an adjusted p-value cutoff of 0.05, we would detect a fraud ring on the fourth application occurrence, with approximately a 5% chance that we would detect the fraud ring earlier (the case that there are non-fraudulent applications). Using a Bonferroni-adjusted p-value cutoff of 0.05 is very conservative here: it suggests that the probability that a false positive SSN5 is flagged would be around 0.05.
Considering these cutoffs, this is one reason we encourage our partners to share loan applications with us instead of just applications that make it through some initial credit check: detection on the fourth application is much cheaper than detection at the fourth loan which was about to be made to a synthetic! Additionally, this provides a clear example of why we have to be careful to deduplicate identities: if somebody reapplies just a few times, they will start triggering these cutoffs, and the test becomes more a test of applicants re-applying than detecting fraud rings.
Depending on whether you are using this p-value or a transformed version of it as an input to a model or as an independent rule, you might want to spend more time tuning the cutoff. Even without looking at your data, you can create simulations and see different false positive rates you might expect, as well as different rates of synthetic fraud you might capture under different simulations. Something to make these values more readable for either a nontechnical human or a model might be applying logs to the p-values as a feature transformation.
If feeding these features into a model, the model choice will affect how you use these features. If creating a feature for a tree-based model, for example, you naively wouldn’t even have to use p-values, and you could instead use counts or frequencies of the SSN5 as a feature here, since any strictly monotonic transformation of a feature will be equivalent for a tree-based model. I write “naively” because there will be productionalization challenges as you try to account for changing volume within different time windows under consideration, which might push you back towards using p-values.
Reflections
There are a few benefits of using this method to detect synthetic fraud. One is that it helps you catch patterns of fraud that have made it through your system which you might have continued to miss. Additionally, once this signal has been triggered, you learn that a fraud ring may be hitting you and you can focus your verification policies or manual review better. Furthermore, this signal could help you identify other approved applications with the same SSN5 might also be synthetic, which helps you revisit your approvals and pinpoint approvals you might not have otherwise realized are fraud, or only realized at the point of charge-off.
However, there are some challenges with this method of synthetic fraud detection. One is that tuning these signals can be a bit challenging, especially if you’re restricting by other attributes that you might expect a fraud ring to have in common. Particularly for an organization without precise synthetic fraud labels, tuning these offline in a way that will work well in production is hard to get right. There are also some production challenges which I hinted at in the technical note above.
Another issue with this sort of feature that it does not kick in immediately. It can take a few applications to realize that something unusual is occurring, and of course you’d like to detect these fraud rings as soon as possible. This is one advantage that SentiLink has relative to lenders working in isolation: because we receive data from many lenders, we are internally able to pool data and note suspicious signs.
Subscribe
Share
Related Content

Blog article
June 26, 2026
We Went Looking for a Missing Corvette. We Found a Machine for Laundering Cars
Read article
Blog article
June 16, 2026
Where Do Fraudsters Start With Stolen Identities?
Read article
Blog article
June 10, 2026
$1.8 Million in Cars Went Missing. Could a Machine Learning Model Have Prevented It?
Read article